
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
用夏普比率分析股票的风险和回报 ——带着Python玩金融(7)
发布时间:2019-01-10
当你进行投资时,仅选择回报高的项目吗?当然不是,你还会综合考虑风险。风险和回报,就像硬币的两面,总是相伴而行的。那么如何来权衡这两者呢?本文将带你使用夏普比率这一金融工具,来评估股票的绩效表现,并在Python中进行实践。
0. 什么是夏普比率?
夏普比率(Sharpe Ratio)是由诺贝尔奖得主威廉·夏普提出的,用以帮助投资者比较投资的回报和风险。理性的投资者一般都是固定所能承受的风险,追求最大的回报;或者在固定预期回报,追去最小的风险。所以夏普比率计算的是,每承受一单位的总风险所产生的超额回报。计算公式如下:
其中

分子计算了差值,说的是将某项投资与代表整个投资类别的基准进行比较,得到超额回报。分母标准差代表收益的波动率,对应着风险,因为波动越大预示着风险越高。
1. 获取数据
接下来,我们将通过Python编码,使用夏普比率来分析 Amazon 和 Facebook 这两家公司的股票,并将标普500指数做为比较的基准。
首先导入相应的 Python 包,并进行一些设置。
# 导入Python包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 绘图设置
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.style.use('fivethirtyeight')
使用 pandas 读取股票数据和标普500数据(点击连接获取原始数据)。
# 读取股票数据
stock_data = pd.read_csv("stock_data.csv",
parse_dates=['Date'], # 将Date列解析为时间格式
index_col = ['Date'] # 设置Date列为索引
).dropna() # 丢弃包含缺失值的行
# 读取标普500数据
benchmark_data = pd.read_csv("benchmark_data.csv",
parse_dates=['Date'],
index_col = ['Date']
).dropna()
2. 了解数据
让我们查看数据的基本信息以及前几行数据,从而对数据有个整体印象。
# 显示股票数据
print('Stocks\n')
stock_data.info() # 数据的基本信息
print(stock_data.head()) # 输出前5行数据
# 显示标普500数据
print('\nBenchmarks\n')
benchmark_data.info()
print(benchmark_data.head())
Stocks
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 252 entries, 2016-01-04 to 2016-12-30
Data columns (total 2 columns):
Amazon 252 non-null float64
Facebook 252 non-null float64
dtypes: float64(2)
memory usage: 5.9 KB
Amazon Facebook
Date
2016-01-04 636.989990 102.220001
2016-01-05 633.789978 102.730003
2016-01-06 632.650024 102.970001
2016-01-07 607.940002 97.919998
2016-01-08 607.049988 97.330002
Benchmarks
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 252 entries, 2016-01-04 to 2016-12-30
Data columns (total 1 columns):
S&P 500 252 non-null float64
dtypes: float64(1)
memory usage: 3.9 KB
S&P 500
Date
2016-01-04 2012.66
2016-01-05 2016.71
2016-01-06 1990.26
2016-01-07 1943.09
2016-01-08 1922.03
从中我们知道这里有2016年所有交易日的数据,包括 Amazon 和 Facebook 的股价以及标普500指数。
3. 观察股票数据
在比较股票数据和标普500指数之前,先让我们绘制股价随时间波动的折线图,以便更好地理解数据。
# 股价可视化
_ = stock_data.plot(subplots=True, title='股票数据')
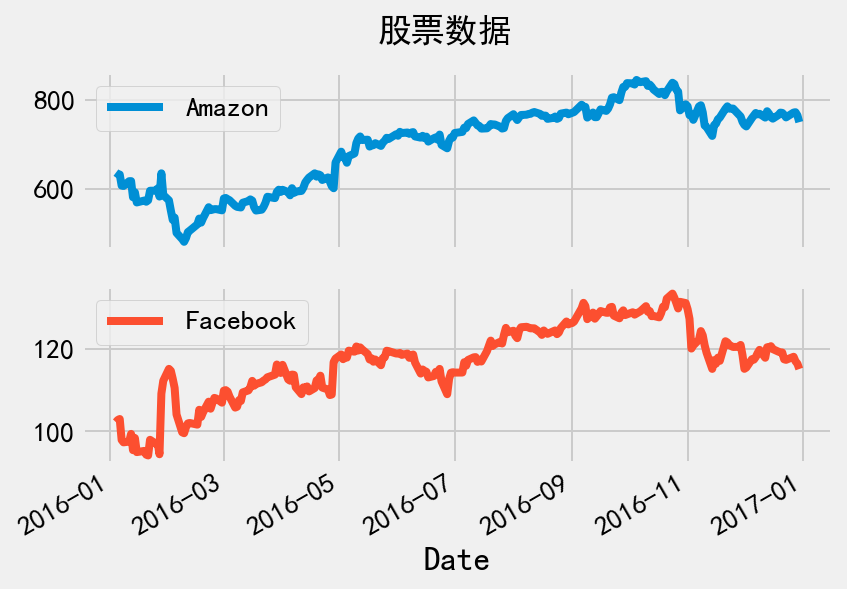
同时也观察下两只股票的统计量,包括均值、标准差、最大最小值,百分位数等。
# 股价的统计量
print(stock_data.describe())
Amazon Facebook
count 252.000000 252.000000
mean 699.523135 117.035873
std 92.362312 8.899858
min 482.070007 94.160004
25% 606.929993 112.202499
50% 727.875000 117.765000
75% 767.882492 123.902503
max 844.359985 133.279999
4. 观察标普500数据
让我们用同样的方法观察作为基准的标普500数据。
# 绘图
_ = benchmark_data.plot(title='标普500指数')
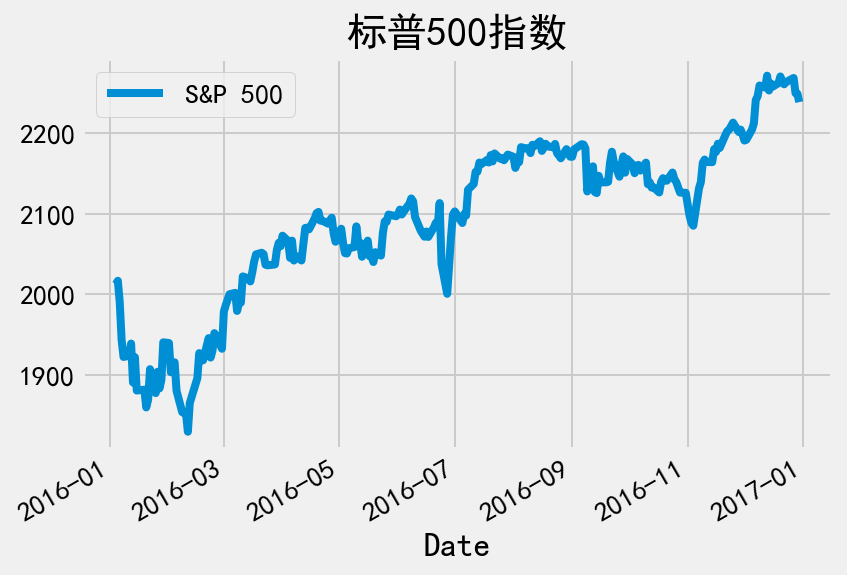
# 统计量
print(benchmark_data.describe())
S&P 500
count 252.000000
mean 2094.651310
std 101.427615
min 1829.080000
25% 2047.060000
50% 2104.105000
75% 2169.075000
max 2271.720000
5. 股票回报率
要计算夏普比率,首先要知道股票的回报率,即当天股价减去前一天股价,得到的差值与前一天股价的比值。这里使用的是历史数据,只能算是马后炮了。
# 计算每日股票回报率
stock_returns = stock_data.pct_change()
# 回报率绘图
stock_returns.plot()
# 回报率统计量
print(stock_returns.describe())
Amazon Facebook
count 251.000000 251.000000
mean 0.000818 0.000626
std 0.018383 0.017840
min -0.076100 -0.058105
25% -0.007211 -0.007220
50% 0.000857 0.000879
75% 0.009224 0.008108
max 0.095664 0.155214
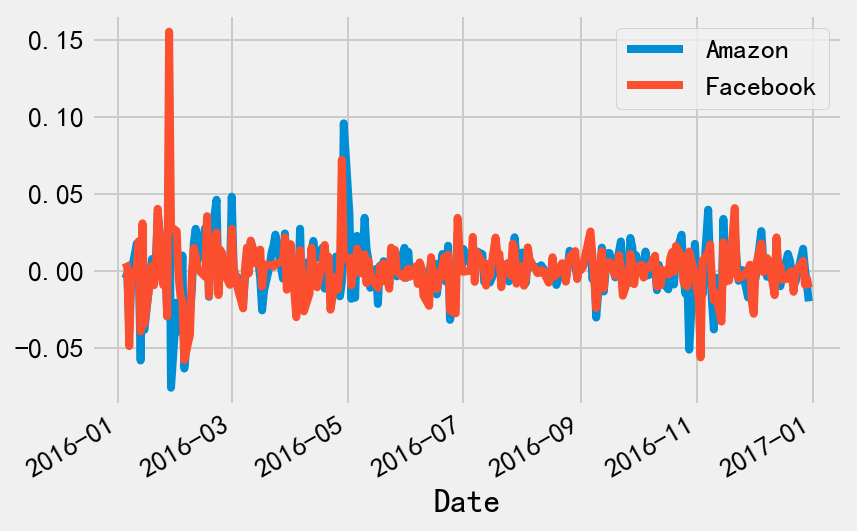
6. 标普500指数回报率
使用同样的方法,我们来查看标普500指数的回报率。
sp_returns = benchmark_data['S&P 500'].pct_change()
sp_returns.plot()
print(sp_returns.describe())
count 251.000000
mean 0.000458
std 0.008205
min -0.035920
25% -0.002949
50% 0.000205
75% 0.004497
max 0.024760
Name: S&P 500, dtype: float64
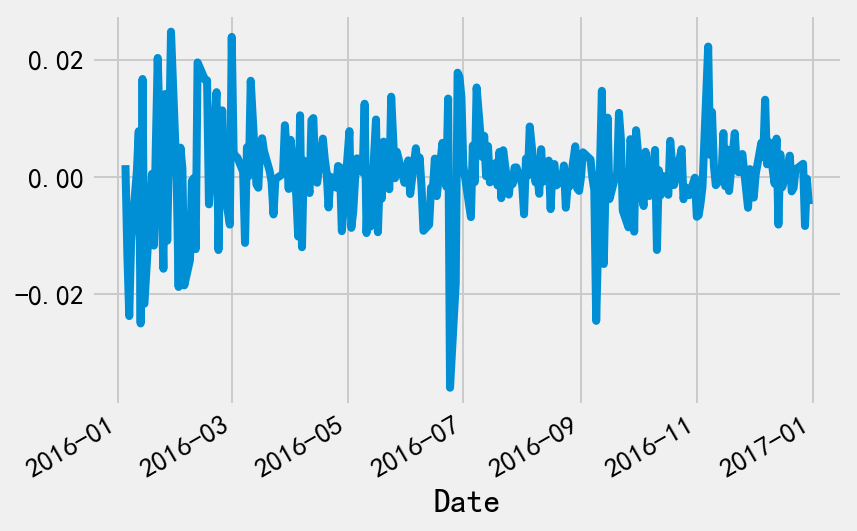
7. 每日超额回报
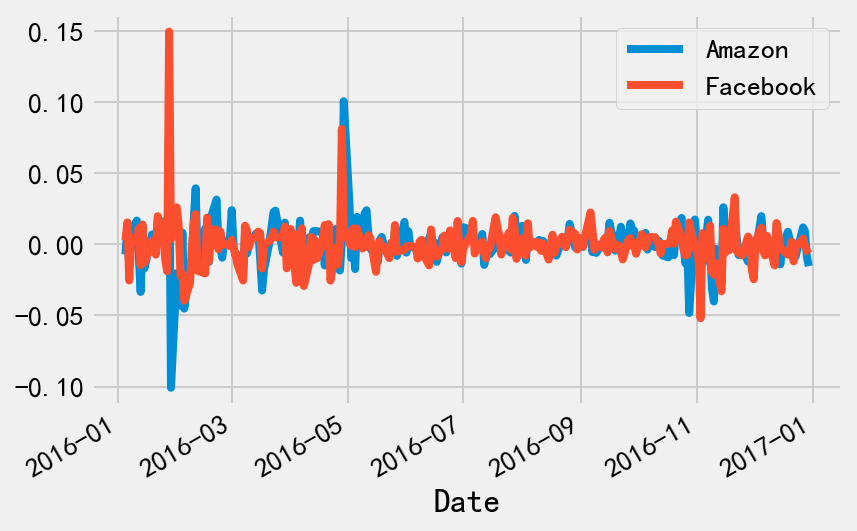
将股票收益和作为基准的标普500收益做比较,计算每日超额回报,即将股票回报率减去标普500的回报率。
excess_returns = stock_returns.sub(sp_returns, axis=0) # 做减法
excess_returns.plot()
print(excess_returns.describe())
Amazon Facebook
count 251.000000 251.000000
mean 0.000360 0.000168
std 0.016126 0.015439
min -0.100860 -0.051958
25% -0.006229 -0.005663
50% 0.000698 -0.000454
75% 0.007351 0.005814
max 0.100728 0.149686
8. 超额回报的均值
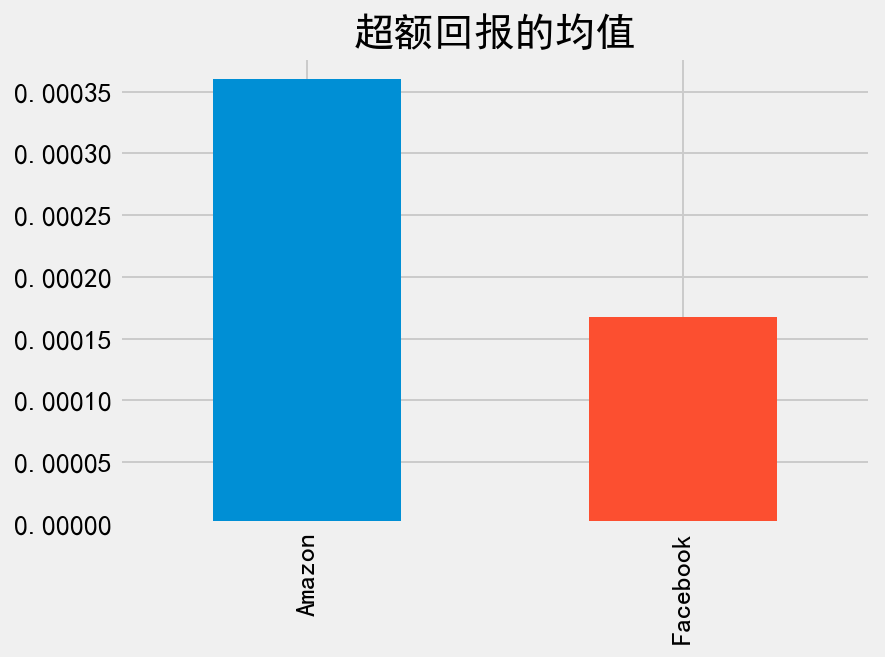
现在我们可以计算夏普比率公式中的分子部分,即每日超额回报的均值,使用 .mean() 方法。
avg_excess_return = excess_returns.mean()
print(avg_excess_return)
Amazon 0.000360
Facebook 0.000168
dtype: float64
将上述结果绘制成条形图便于直观比较,我们发现 Amazon 的回报更高。
_ = avg_excess_return.plot.bar(title='超额回报的均值')
9. 超额回报的标准差
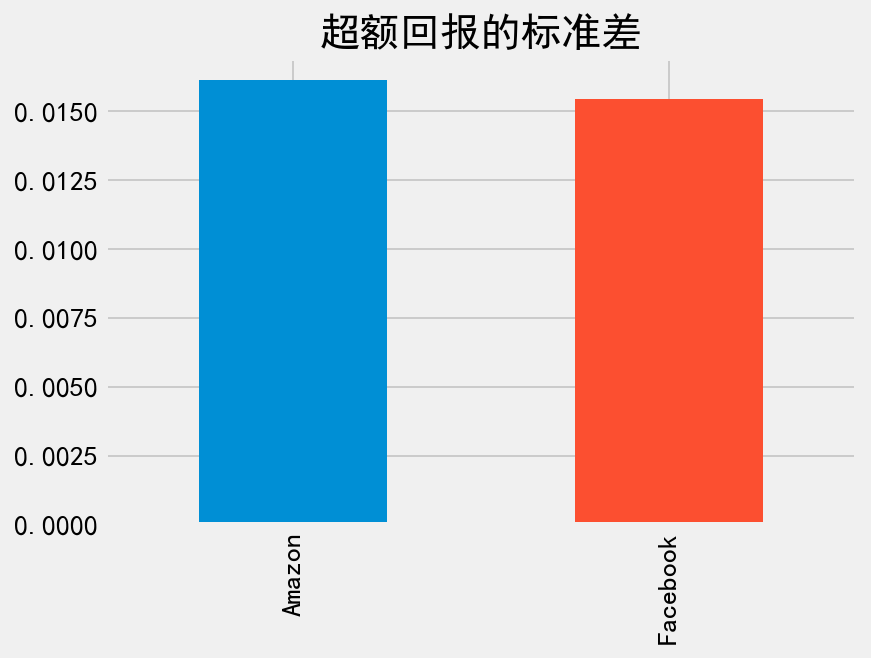
接着我们计算夏普比率公式的分母,即超额回报的标准差,使用 .std() 方法。
# 计算标准差
sd_excess_return = excess_returns.std()
print(sd_excess_return)
Amazon 0.016126
Facebook 0.015439
dtype: float64
同时,绘制标准差的条形图,我们发现 Amazon 和 Facebook 的标准差比较接近。
_ = sd_excess_return.plot.bar(title='超额回报的标准差')
10. 计算夏普比率
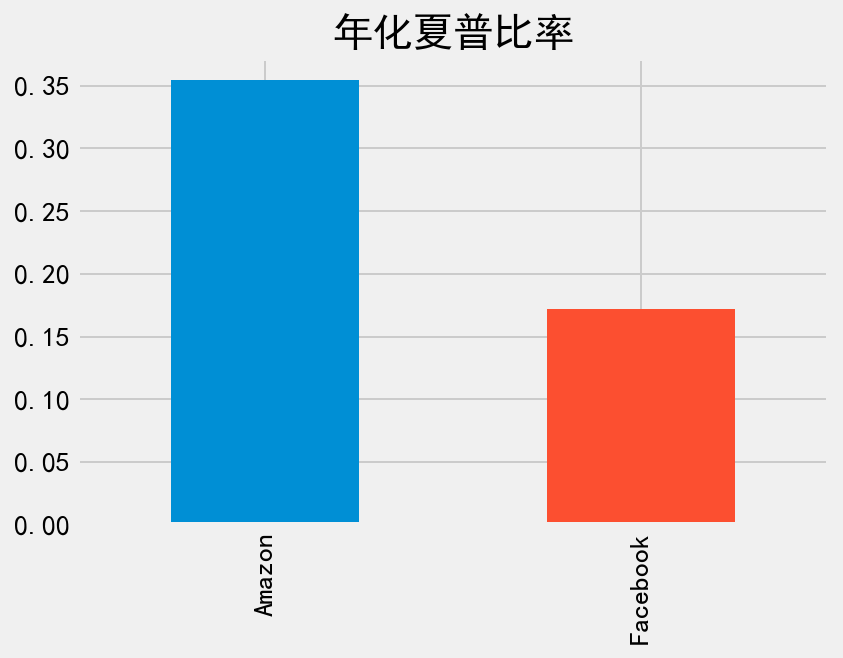
现在万事俱备,只要将超额回报的均值除以其标准差,即可得到衡量回报和风险的夏普比率了。另外我们需再乘上
# 日夏普比率(.div 做除法)
daily_sharpe_ratio = avg_excess_return.div(sd_excess_return)
# 年化夏普比率(.mul 做乘法)
annual_factor = np.sqrt(252)
annual_sharpe_ratio = daily_sharpe_ratio.mul(annual_factor)
print(annual_sharpe_ratio)
Amazon 0.354283
Facebook 0.172329
dtype: float64
计算得出 Amazon 的夏普比率差不多是 Facebook 的两倍。我们仍用条形图来可视化这一结果。
_ = annual_sharpe_ratio.plot.bar(title='年化夏普比率')
小结
根据上述计算的夏普比率,我们应该投资哪只股票呢?当然是 Amazon 了,因为它的夏普比率是 Facebook 的两倍多。这也意味着承受相同风险的情况下,Amazon 的收益更高。当然这里作为练习使用的是历史数据,并不能当做实际投资的依据。
注:本文基于 DataCamp 项目 Risk and Returns: The Sharpe Ratio 撰写而成。
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



