
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
Hadoop系列之yarn架构与流程浅析
发布时间:2019-01-15
Yarn介绍
MapReduce 早期的 JobTracker/TaskTracker 机制在可扩展性,内存消耗,线程模型,可靠性和性能存在较大的缺陷, 为从根本上解决框架的性能瓶颈,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,新的 Hadoop MapReduce 框架命名为Yarn。
yarn架构入下图(引用自官网)
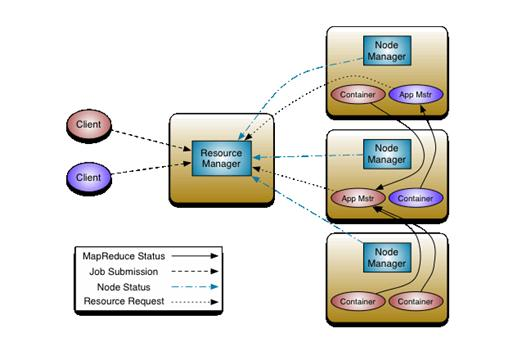
yarn架构由client代理、ResourceManager、NodeManager、Container以及计算框架主服务AppMaster几个基本元素构成。
ResourceManager
主要职责是:调度、启动每个Job所属的ApplicationMaster、另外监控 ApplicationMaster的存在情况。ResourceManager负责作业与资源的调度。接收JobSubmitter提交的作业,按照作业的上下文 (Context) 信息,以及从 NodeManager 收集来的状态信息,启动调度过程,分配一个Container作为 App Mstr。
ApplicationMaster
yarn并不知道MR程序的运行机制,会启动一个ApplicationMaster来进行管理。 ApplicationMaster 负责一个 Job 生命周期内的所有工作,向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。注意每个Job都有一个ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
NodeManager
是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
容器
在nodeManager内部,可以理解为一个资源池,类似于jvm虚拟机, 包括本次任务需要的CPU, 内存等资源。会把程序的jar包也拷贝到容器内存中。
Yarn工作流程
job从客户端提交到MR结果的输出,yarn是怎样实现的呢? 可以从两个方面考虑这个问题:
1.在yarn运行job的工作流程?
2.yarn框架各个部分协助怎样完成job的?
yarn的工作流程如下图所示:

- job client向ResourceManager提交执行job申请。
- ResourceManager接收job请求, 生成job id, 返回job id, staging工作目录等信息给job client。
- Client把资源jar等拷贝到staging工作目录(hdfs /tmp/xxx/yarn-staging/jobId)
- ResourceManager把job放入工作队列。
- NodeManager从ResourceManager队列中领取任务。
- ResourceManager根据job和NodeManager情况, 计算出资源大小,并创建Container。
- 创建MRAppMaster(如果计算框架是MR),运行在Container上。
- MRAppMaster向ResourceManager注册。
- MRAppMaster创建Map, Reduce task任务进程(yarn child)。
- Map/Reduce任务完成, 然后向ResourceManager注销MRAppMaster进程。
补充:
jar提交给集群运行方法
- 将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wordcount.jar com.exaple.wordcount.WCRunner
- 在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar");
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



