
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
Web Scraper 入门教程(第8课):召唤世界的咒语
发布时间:2018-07-03

日本平安时代中期的阴阳师安倍晴明曾说,“名字是最短的咒语”。
当大家还没有看到正文之前,他已经接触了文章的名字,文章的题目是先于文章给到读者的体验。为文章起一个好名字的重要性再怎么说都不过分。
如何给文章起个好题目呢,自然是先跟高手学了。今天咱们就以抓取简书 7 日热门文章标题为例,开始 Web Scraper 入门教程(第8课) 的学习。

一、Text 选择器
回想下第 7 课第一部分选择器的定义及分类,我们应该使用哪种选择器提取文章标题呢,顾名思义,自然是 Text(文本)选择器啦。下面开始实操:
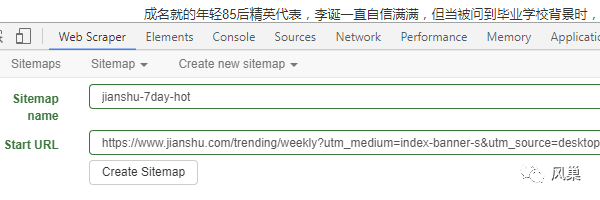
1)先进入简书7日热门页面,网址:
https://www.jianshu.com/trending/weekly?utm_medium=index-banner-s&utm_source=desktop
2)建立 Sitemap:
3)点击 Add new Selector 建立选择器:
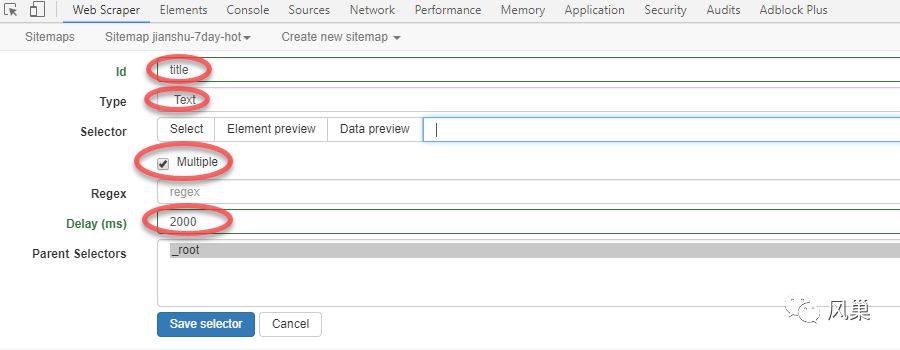
填写原则见第 7 课第二部分设定选项。
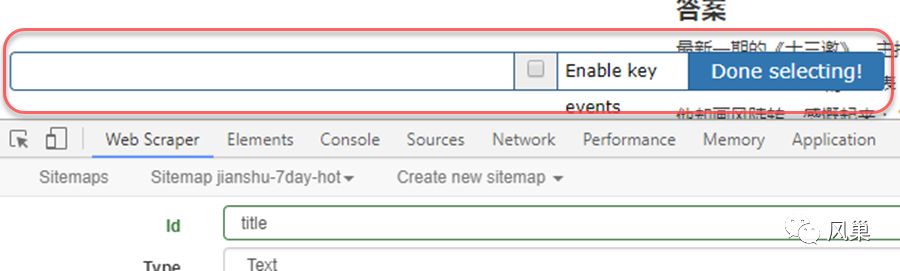
3)然后点击 Selector 后「Select」按钮选择元素,注意点击此按钮后,开发者工具栏后会出现以下「选择工具条」。
4)按以下动图选择元素:
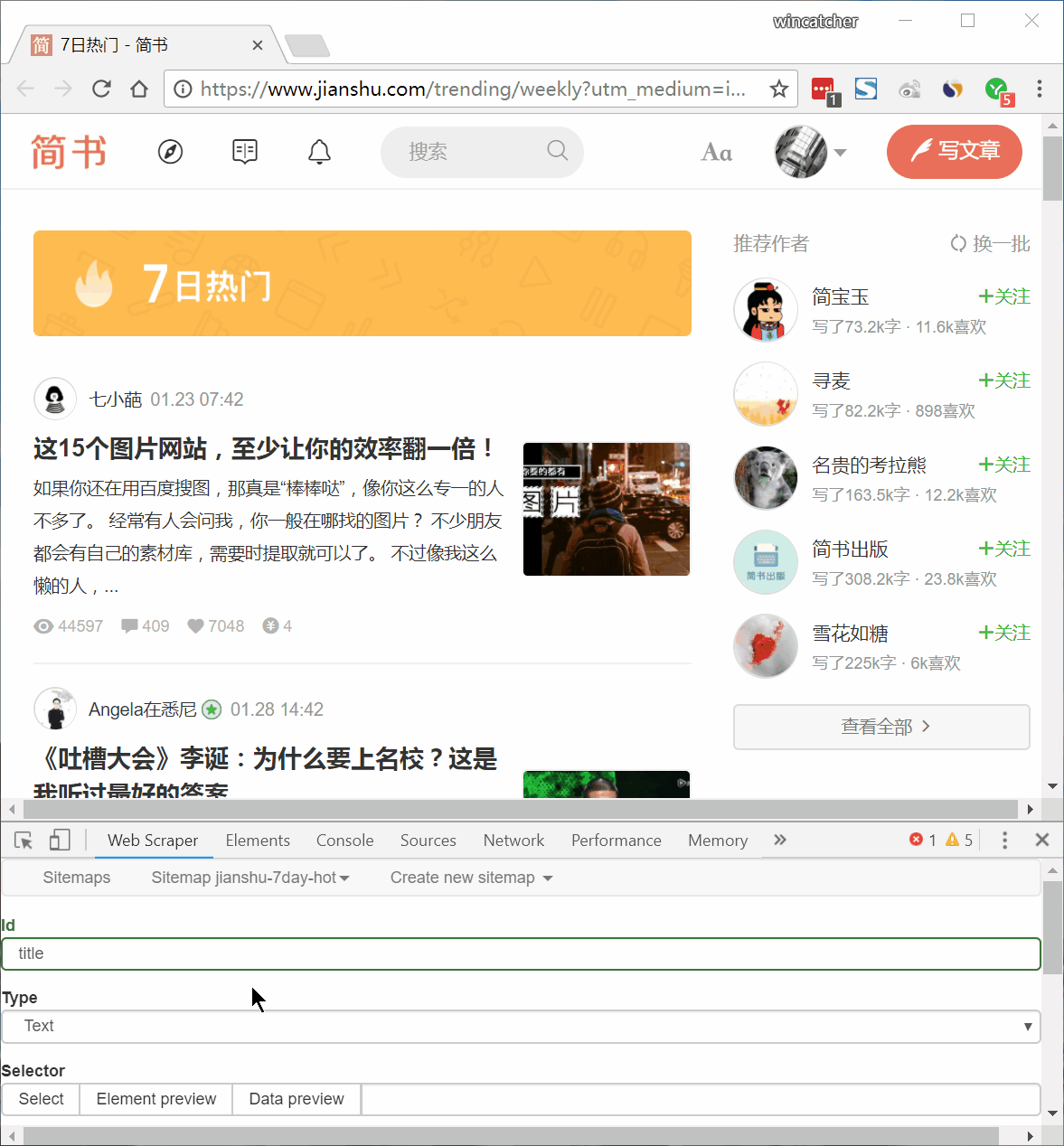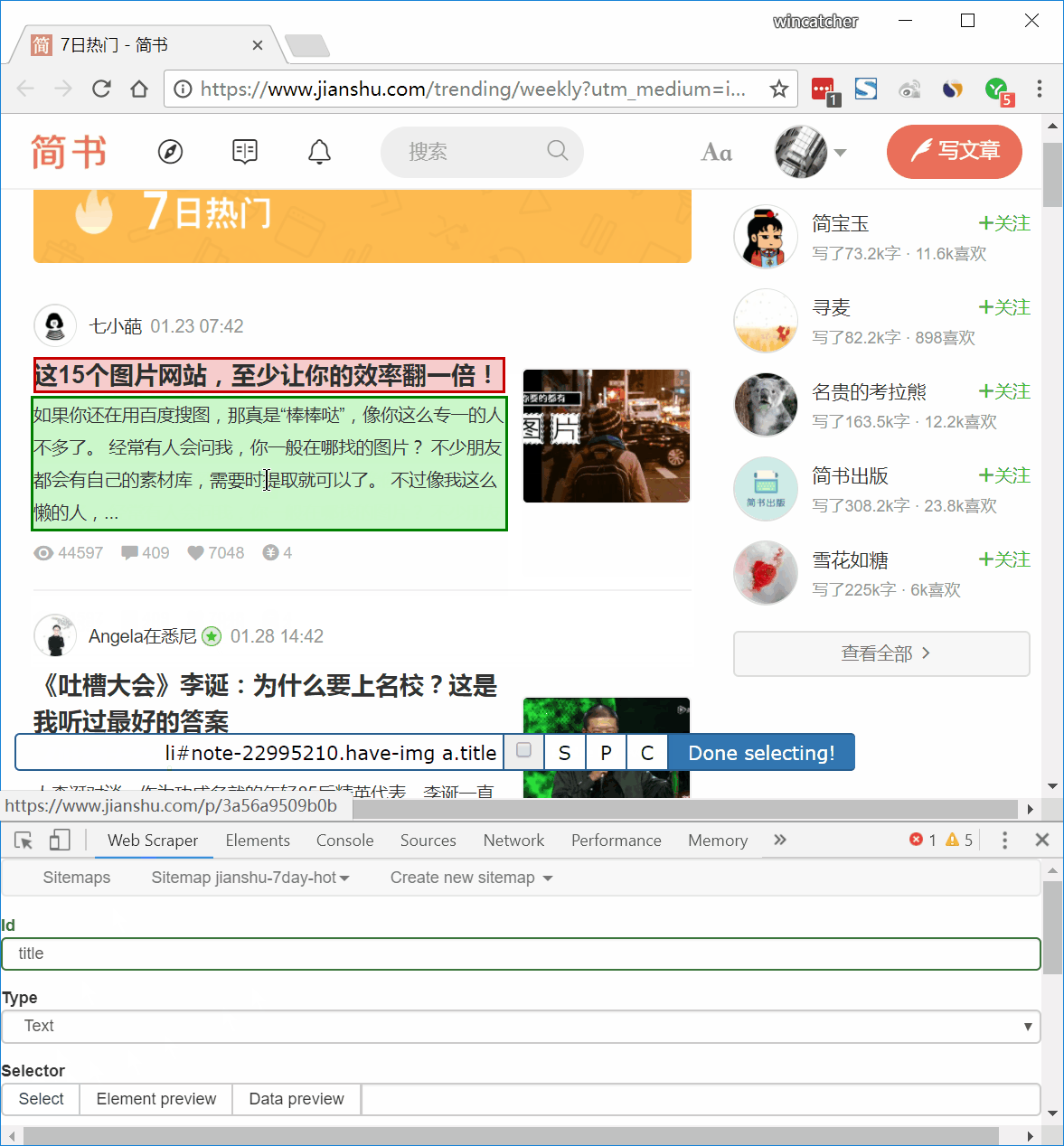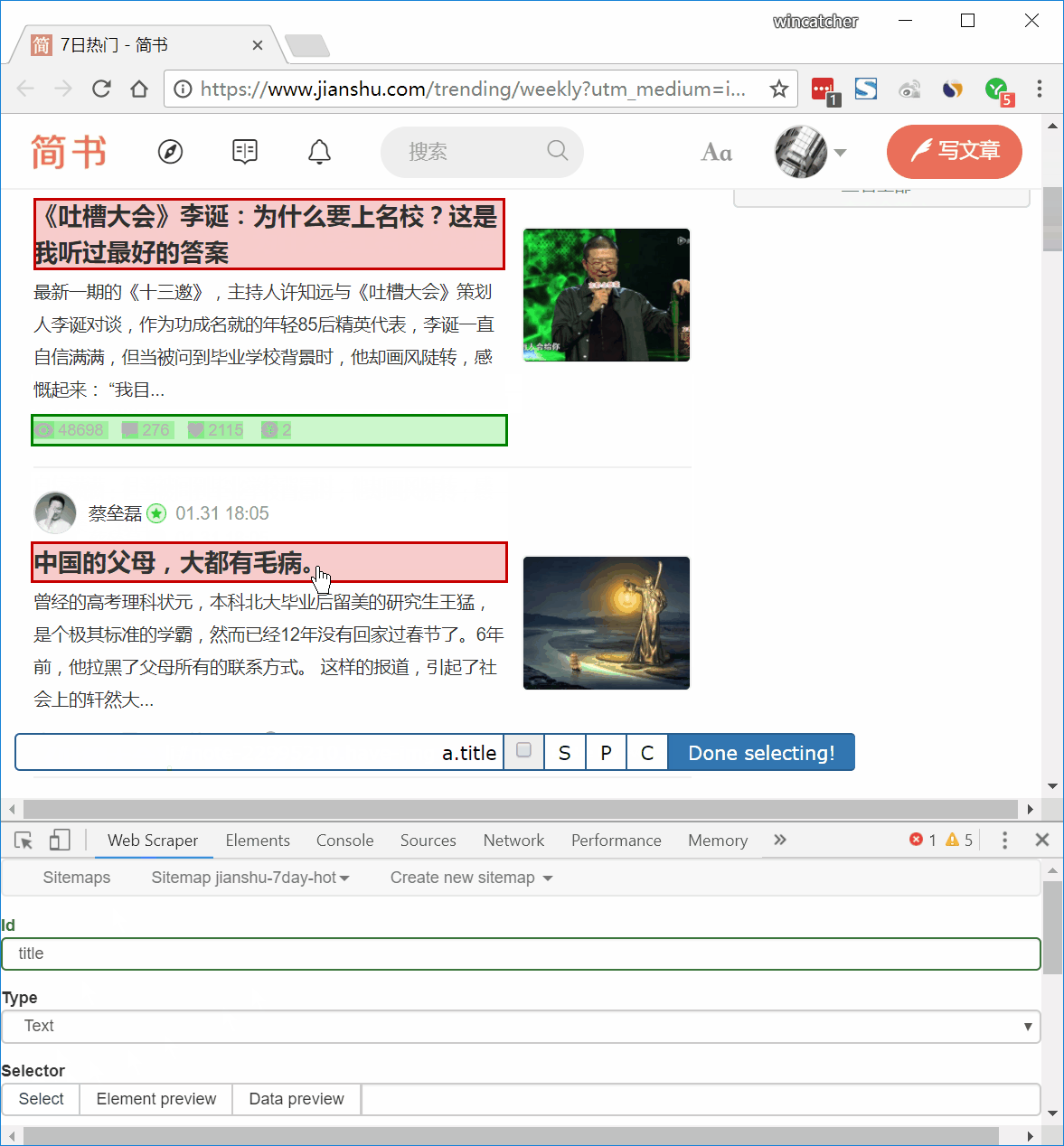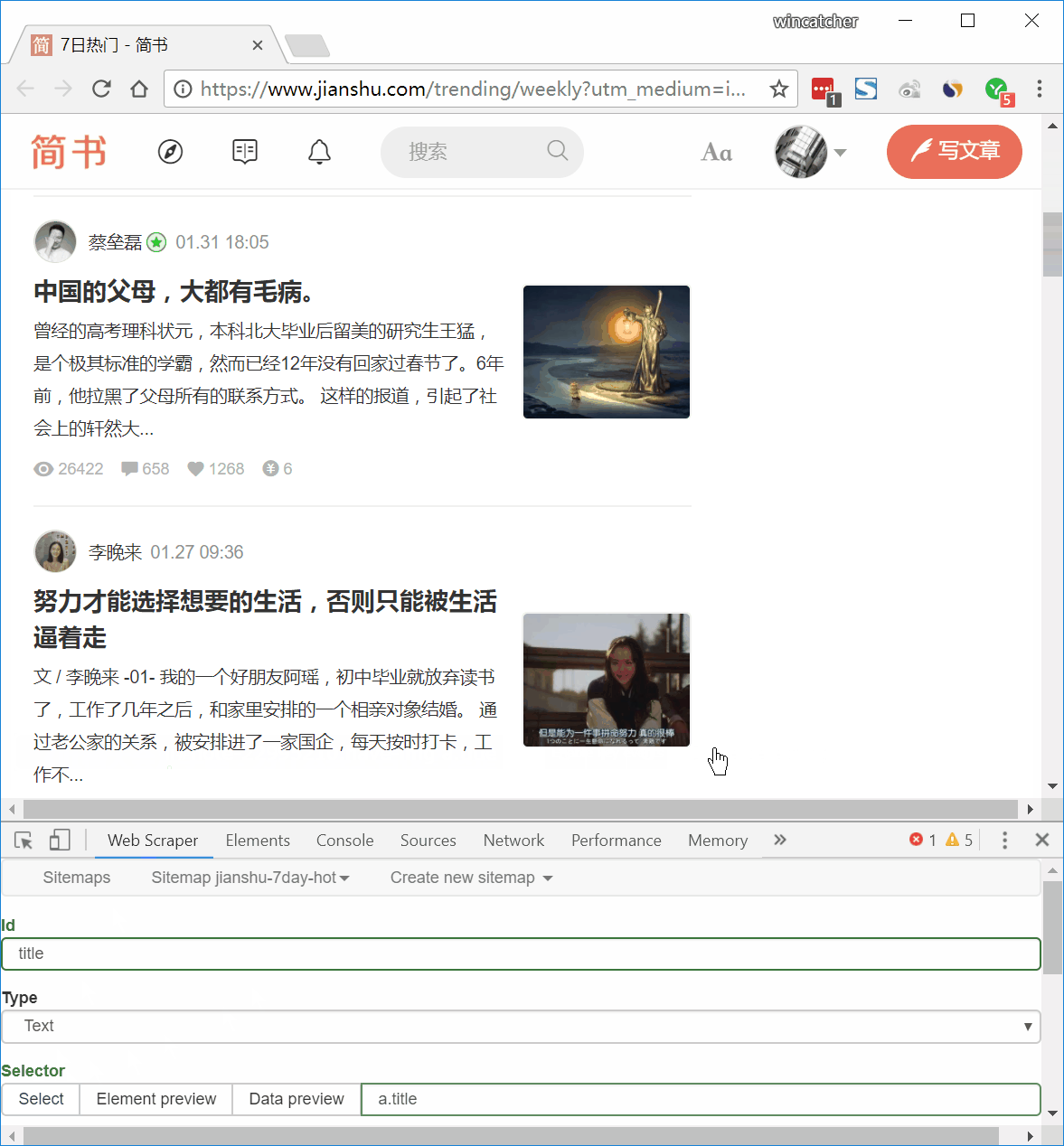
流程如下:
1、鼠标移到第 1 篇文章标题上方。注意鼠标移过区域会变为绿色,多尝试几次,如上图只选中标题(只有标题部分变为绿色),而不要包含其他内容。随后点击鼠标,选中部分会变为红色。
2、照此炮制,选中第 2 篇文章标题。
3、向下浏览,所有文章标题均变为红色,如仍有未变为红色标题,照以上步骤点击即可。
4、点击 Down selection 完成选择。
5、点击 Save selection 保存选择器。
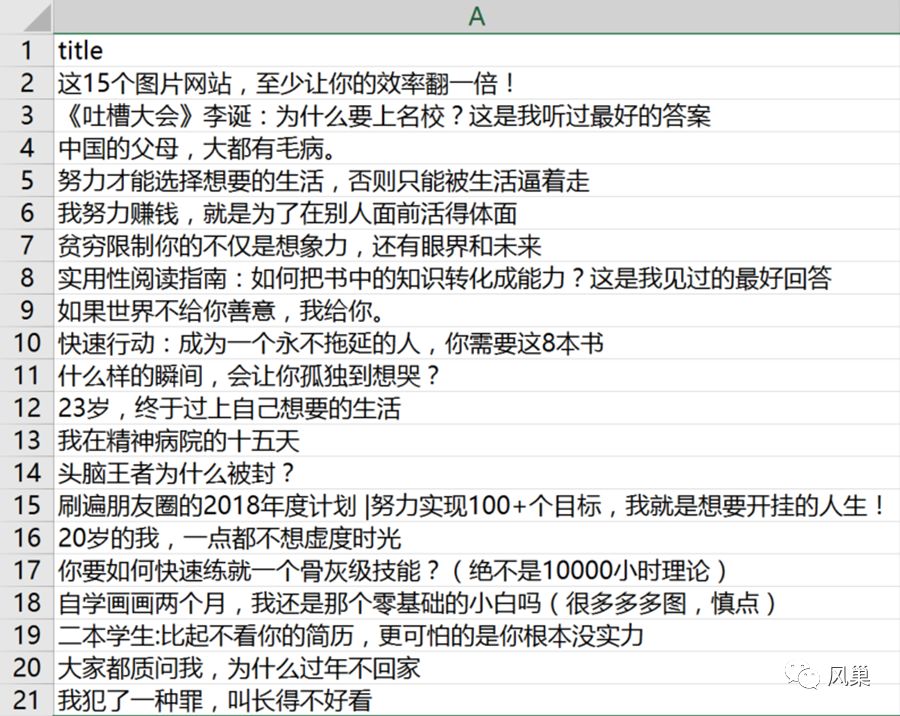
6、按照第 5 课第二部分数据抓取示例抓取并导出 Excel 表格,抓取完成。整理后如下表。
二、选择器原理
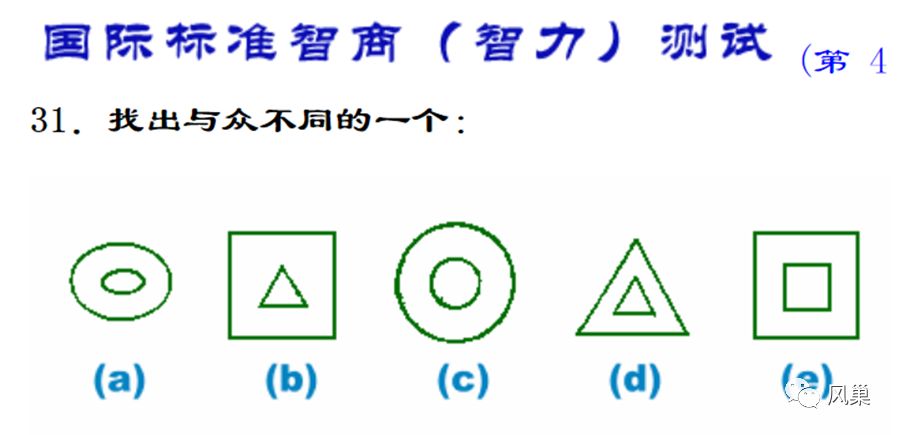
相信上面的智商测试题大家都见过不少,找出规律,剔除与众不同那个。
选择器也是同理,网页中每个元素都有自己的样式,选择器就是根据已选元素的相同点自动选择同类元素。
举个栗子
在进行选择时,选中第 1 篇文章标题后,「选择工具条」中内容如下图:
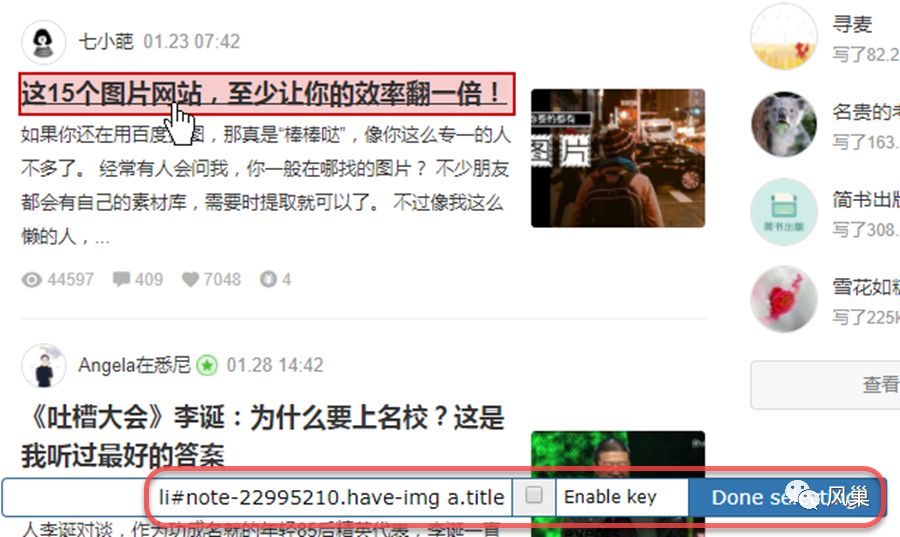
随后点击 Select 重置选择器,重新选择第 2 篇文章标题后,「选择工具条」中内容如下图:
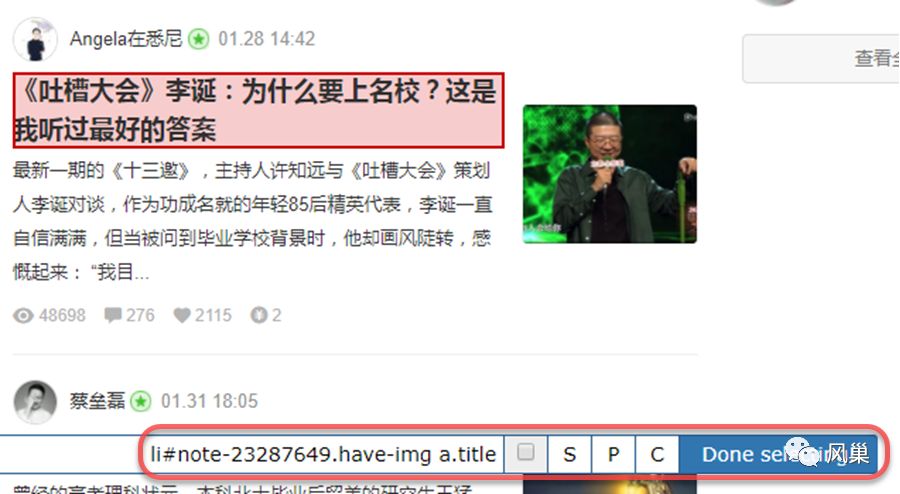
两者有啥共同点?
你重新按第 1 篇文章标题,第 2 篇文章标题的顺序选择下,「选择工具条」中内容变为:
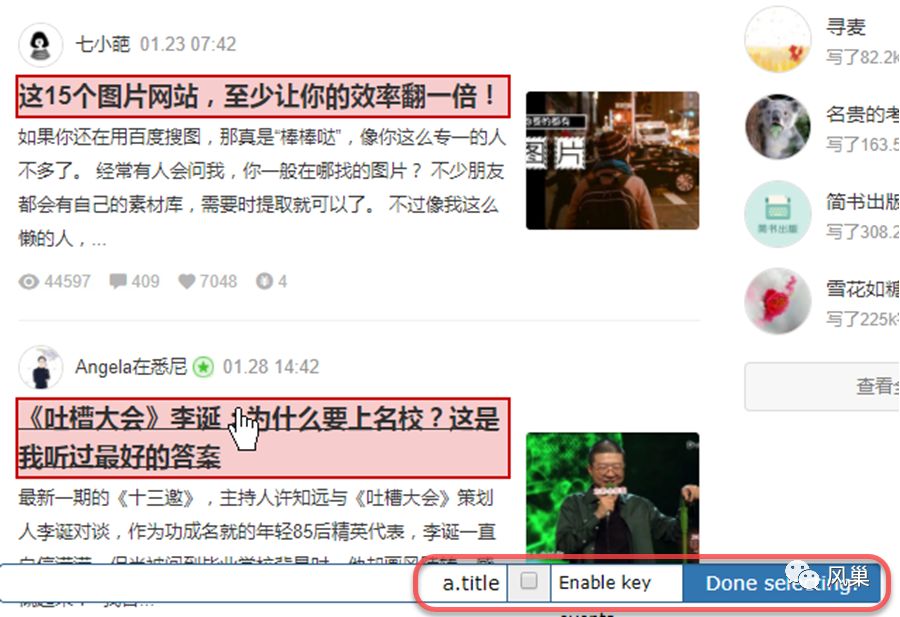
然后点击 Done selecting 确认,Selector 中内容:
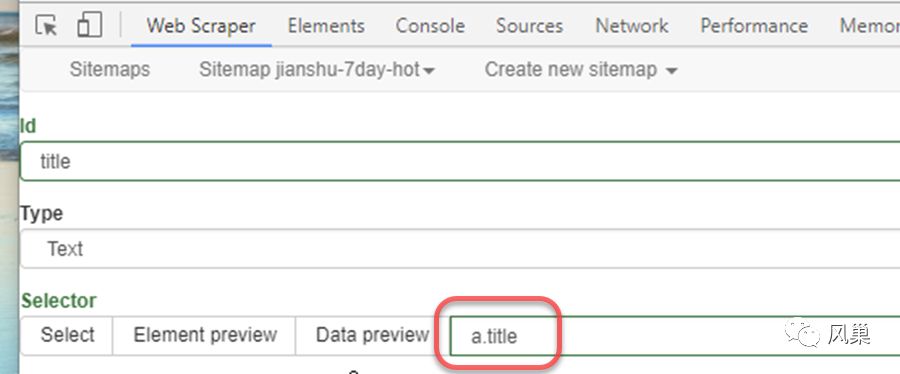
没错,两者的共同点是拥有 a.title 这个属性。
三、互动环节
基本道理懂了,细节方面呢?自己尝试呗。习题如下:
1、试试从第 2 篇文章开始抓取,第 3 篇呢,隔着抓呢?结果有何不同?
2、从第 1 篇选择标题,从 2 篇选择文章简介呢?
3、每篇文章有以下元素:作者、发表日期、标题、简介、阅读数、评论数、点赞数、赞赏钱数,都有哪些可以用 Text 选择器进行抓取?
这节课就到这里,下节课咱们讲 Image(图片)选择器,哈哈,某些人要暗爽啦 。

【福利】
1、回复wsdd,获取我翻译的《Web Scraper官方文档》。
2、回复wssm,获得 各大常见网站 Sitemap 示例,此列表还会持续更新。
3、我建了个在线文档 「爬虫学习材料梳理」,网址:
https://shimo.im/docs/qc5HJYODsNQJcL6k/
4、我组建了一个免费微信群 共同打磨爬虫技能,回复 社群 了解加入方式,一起切磋,互开脑洞。
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



