
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
SQL中查询效率优化
发布时间:2018-07-03
使用索引
首先我们看下百度百科上的解释:
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引是独立于表的一中物理存储结构,当我们语句中用到索引的字段的时候,数据库会首先去索引中查找满足条件的数据的索引值(相当于页码),然后在根据索引值去表中筛选出我们的结果。
当我们使用索引和不使用索引的时候,效率会相差相当大,特别是当数据量越来越大的时候。
另外需要注意的是并不是我们在where条件里面用有索引的字段进行筛选数据库在查询的时候就会走索引,有些写法会让数据库不走索引,接下来会总结一些会让查询进行全表扫描而不走索引的写法;
提防ORACLE中的数据隐式转换,这个常常是容易被忽略的。
例如:
我们现在有USERS表,现在我们通过AGE字段查询年龄等于14的学生,字段AGE是INT类型,且有建索引,语句如下:SELECT * FROM USERS WHERE AGE = '14'由于AGE是INT类型,当你写语句的时候在14上加上了单引号('),其实语句就变成了如下SELECT * FROM USERS WHERE TO_CHAR(AGE) = '14'这就会导致索引失效进行全表扫描了。避免使用‘<>’和‘!=’,也会导致不走索引而进行全表扫描;
尽量避免使用‘or’,当我们在where中使用or来进行条件连接的时候也有可能会导致全表扫描,这取决于索引类型。
例如:
查询姓名等于张三或者李四的学生,语句SELECT * FROM USERS WHERE NAME='张三' OR NAME = '李四'可以改为SELECT * FROM USERS WHERE NAME='张三' UNION ALL SELECT * FROM USERS WHERE NAME='李四'来进行查询。注意通配符的使用,当%前置的时候会导致索引失效进行全表扫描。
例如:
查询姓名中包含‘文’的学生,语句SELECT * FROM USERS WHERE NAME LIKE '%文%'可以改为SELECT * FROM USERS WHERE INSTR(NAME,'文') >0来进行查询。
执行顺序
其实为什么要知道查询执行的逻辑顺序,原因很简单,为了尽量早的筛选出我们想要的数据,将不需要的数据进行计算是需要成本的,直观的表现就是查询变慢。
查询的执行顺序:
(8)SELECT (9)DISTINCT (11)<TOP NUM> <SELECT LIST>
(1)FROM [LEFT_TABLE]
(3)<JOIN_TYPE> JOIN <RIGHT_TABLE>
(2)ON <JOIN_CONDITION>
(4)WHERE <WHERE_CONDITION>
(5)GROUP BY <GROUP_BY_LIST>
(6)WITH <CUBE | ROLLUP>
(7)HAVING <HAVING_CONDITION>
(10)ORDER BY <ORDER_BY_LIST>
另外当WHERE后跟了多项筛选条件的时候,执行顺序是自右向左/自下向上,所以我们可以把能大量筛选掉数据的条件写在最后。
SELECT *
FROM USERS
WHERE test1 = '1'
AND test2 = '2'
test1和test2都是两个不存在的字段,执行的时候会如下报错:
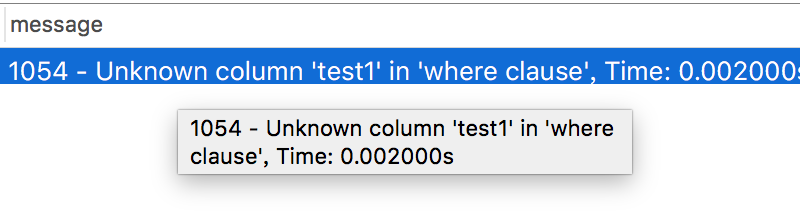
其他
- 减少不必要的计算,例如ORDER BY/DISTICT等;
- IN和EXISTS的选择;
IN适合内表小外表大的情况,而EXISTS适合外表小内表大的情况。
NOT IN 和NOT EXISTS时候选择NOT EXISTS,NOT IN不走索引。 - 使用
SELECT 字段名来代替SELECT *; - 表连接的选择;
优先级:
INNER JOIN > LEFT/RIGHT JOIN > FULL JOIN
这三者差别比较大,不影响结果的情况下选择前者。ON尽量选择主键/外键进行连接,另外在ON中我们也可以对数据惊醒筛选,我们在上面的执行顺序中是可以看到ON的执行顺序是非常靠前的。
另外有点需要注意的是,当使用LEFT JOIN的时候,如果在WHERE中有对右表中的字段进行筛选的时候,结果就等同于INNER JOIN了,RIGHT JOIN 反之。 - FROM多个表的时候将小表写在后面,在CBO优化器情况下默认是将后表当成驱动表的。
写SQL简单,优化SQL难,数据分析师之路长的很,慢慢走~
peace~
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



