
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
新手用python爬虫自己做天气预报查询
发布时间:2018-07-03
最近小编在学习爬虫,就想找个东西练练手,小说、图片、音乐什么的都烂大街了,正好最近天气是越来越冷,小编窝家里自己敲了个天气简单查询的代码,请大家指正下!
先找目标,最终还是选用了中国天气网,url:http://www.weather.com.cn/
找到目标后,开始分析网页,发现里面是支持查询,并且查询的城市和url又一定的规律,如下:
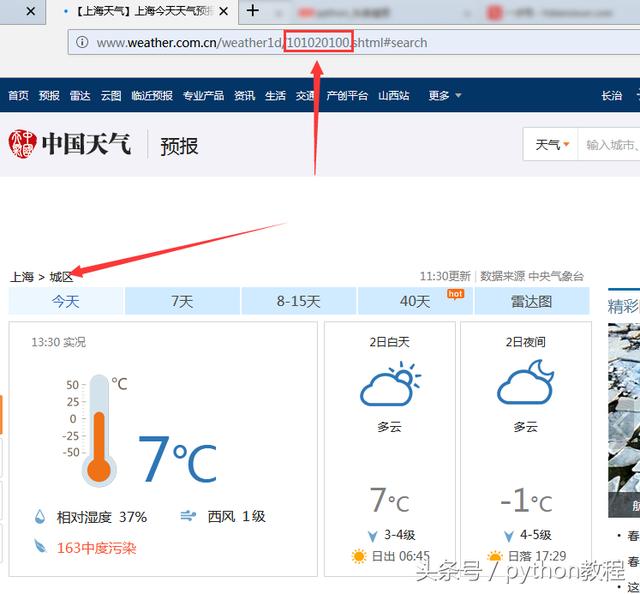
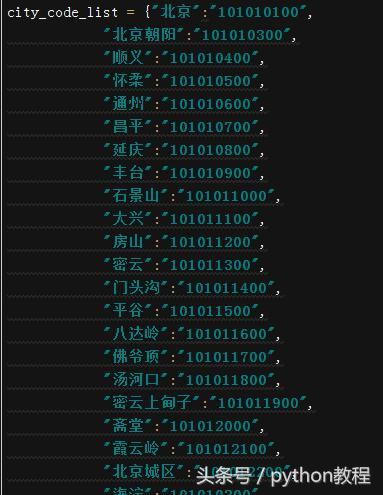
百度下后,发现url中的数字是城市代码,这就简单了,先把代码弄到,然后做成字典。
然后,分析网页的元素,发现近7天的预报都已经整整齐齐的放在那里了,这就简单了,开始写代码吧!
选定方法,这里小编用的是xpath,方便、快捷。
需要提前安装lxml库,然后导入
import requestsfrom lxml import etree
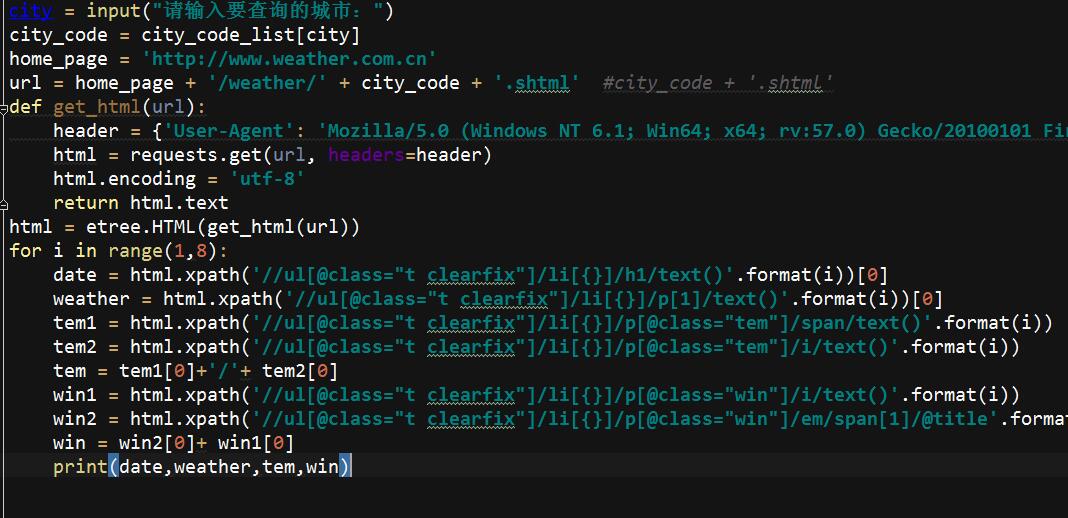
为了方便查询,直接写input,然后拼接网址
city = input("请输入要查询的城市:")city_code = city_code_list[city]home_page = 'http://www.weather.com.cn'url = home_page + '/weather/' + city_code + '.shtml'
解析拼接好的网址,这里小编用requests获取get内容
def get_html(url):header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}html = requests.get(url, headers=header)html.encoding = 'utf-8'return html.texthtml = etree.HTML(get_html(url))
然后开始查找路径
date = html.xpath('//ul[@class="t clearfix"]/li[{}]/h1/text()'.format(i))
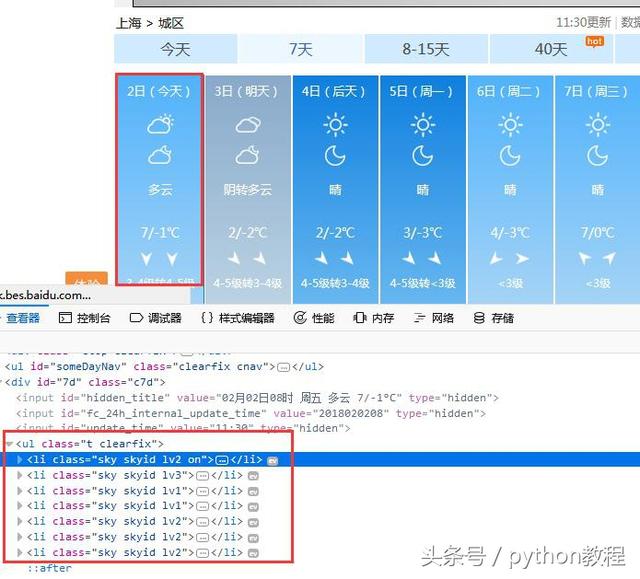
由于7天的预报都是在li标签下的,所以写到循环中,print输出即完成!
最后效果如下:

简单的功能实现,成就感满满的!
代码放上:
喜欢就关注一波呗(^_^),想和小编一起学习Python的,可以 查看小编资料哦。
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



