
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
布隆过滤器-python实现
发布时间:2018-07-03
布隆过滤器是什么?
在爬虫爬取网页的时候,我们会做的一件事情是判断这个网页是否之前已经爬取过。这个检验步骤在之前的文章里我是用了一个#集合#来保存已经爬取过的网页,而在计算机当中,使用hash表来保存。Hash表的好处就是能够快速定位,而它的缺点也众所皆知,就是存储空间的浪费。
为什么会浪费存储空间呢?
- 哈希表方法需要把实实在在的具有特定长度的元素的信息指纹存储在内存或硬盘中的哈希表中(比如每个Email地址对应成一个8字节的信息指纹),这个存储量在实际应用中一般是相当大的。比如每存储一亿个Email地址,需要0.8G大小的数字指纹存储空间,考虑到哈希表的存储空间利用率一般只有一半,所以需要1.6G的存储空间。如果存储几十亿上百亿的Email地址,那就需要百亿字节的内存存储空间。
为了解决空间浪费严重这一问题,我们采用布隆过滤器。
布隆过滤器实际上是一个很长的二进制向量和一系列的随机映射函数。
布隆过滤器是N位的二进制数组,其中N是位数组的大小。它还有另一个参数k,表示使用哈希函数的个数。这些哈希函数用来设置位数组的值。当往过滤器中插入元素x时,h1(x), h2(x), …, hk(x)所对应索引位置的值被置“1”,索引值由各个哈希函数计算得到。注意,如果我们增加哈希函数的数量,误报的概率会趋近于0.但是,插入和查找的时间开销更大,布隆过滤器的容量也会减小。
为了用布隆过滤器检验元素是否存在,我们需要校验是否所有的位置都被置“1”,与我们插入元素的过程非常相似。如果所有位置都被置“1”,那也就意味着该元素很有可能存在于布隆过滤器中。若有位置未被置“1”,那该元素一定不存在。
误报
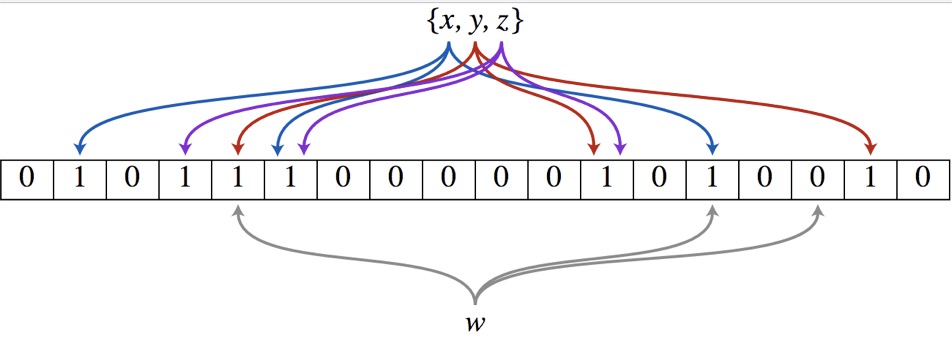
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
from bitarray import bitarray
import mmh3
class BloomFilter(set):
def __init__(self,size,hash_count):
#size:the num of the bitarray
#hash_count:the num of hash function
super(BloomFilter,self).__init__()
self.bit_array = bitarray(size)
self.bit_array.setall(0) #初始化为0
self.size = size
self.hash_count = hash_count
def __len__(self):
return self.size
def __iter__(self):
return iter(self.bit_array)
def add(self,item):
for i in range(self.hash_count):
index = mmh3.hash(item,i) % self.size
self.bit_array[index] = 1
return self
def __contains__(self,item):
out = True
for i in range(self.hash_count):
index = mmh3.hash(item,i)%self.size
if bit_array[index] == 0:
out = False
return out
def main():
bloom = BloomFilter(100,5)
fd = open("urls.txt") #有重复的网址 http://www.kalsey.com/tools/buttonmaker/
bloomfilter = BloomFilter(100,10)
while True:
url = fd.readline().strip()
if (url == 'exit') :
print ('complete and exit now')
break
elif url not in bloomfilter:
bloomfilter.add(url)
# print(url)
else:
print ('url :%s has exist' % url )
if __name__ == '__main__':
main()
urls.txt
http://sourceforge.net/robots.txt
http://sourceforge.net/
http://sourceforge.net/
http://sourceforge.net and https://sourceforge.net
http://sourceforge.net/sitemap.xml
http://sourceforge.net/allura_sitemap/sitemap.xml
http://sourceforge.net/directory_sitemap.xml
http://a.fsdn.com
http://a.fsdn.com/con/img/sftheme/favicon.ico
http://a.fsdn.com/con/js/min/sf.head.js
http://a.fsdn.com/con/js/sftheme/dd_belatedpng.js
http://fonts.googleapis.com
http://fonts.googleapis.com/css
http://a.fsdn.com/con/css/sf.css
http://sourceforge.net/blog/feed/
http://email.playtime.uni.cc/
http://services.nexodyne.com/email/
http://gizmo967.mgs3.org/Gmail/
http://www.hkwebs.net/catalog/tools/gmail/
http://sagittarius.dip.jp/~toshi/cgi-bin/designmail/designmail.html
http://www.eoool.com/
http://sourceforge.netand
https://sourceforge.net
http://a.fsdn.com/con/js/adframe.js
http://sourceforge.net/directory/
http://kalsey.com/tools/buttonmaker/
http://www.lucazappa.com/brilliantMaker/buttonImage.php
http://www.feedforall.com/public/rss-graphic-tool.htm
http://www.yugatech.com/make.php
http://www.hkwebs.net/catalog/tools/buttonmaker/index.php
http://phorum.com.tw/Generator.aspx
http://www.logoyes.com/lc_leftframe.htm
http://cooltext.com/Default.aspx
http://kalsey.com/tools/buttonmaker/
exit
代码运行结果:

布隆过滤器的缺点:
- 无法返回元素本身
布隆过滤器并不会保存插入元素的内容,只能检索某个元素是否存在。 - 删除某个元素
想从布隆过滤器中删除某个元素可不是一件容易的事情,你无法撤回某次插入操作,因为不同项目的哈希结果可以被索引在同一位置。
代码戳:https://github.com/GreenGitHuber/Web/tree/master/crawler
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



