
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
Python爬虫之小猪短租房
发布时间:2018-07-04
前天初步学习了xpath,今天进行一下小练习,爬取小猪短租房北京房源的信息
一、xpath爬取分析
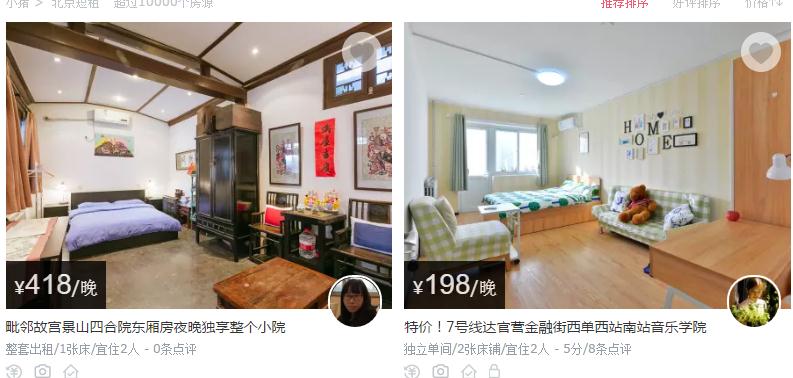
1 爬取的信息有价格,地点,出租类型,床数量,宜居人数,评分,点评数。
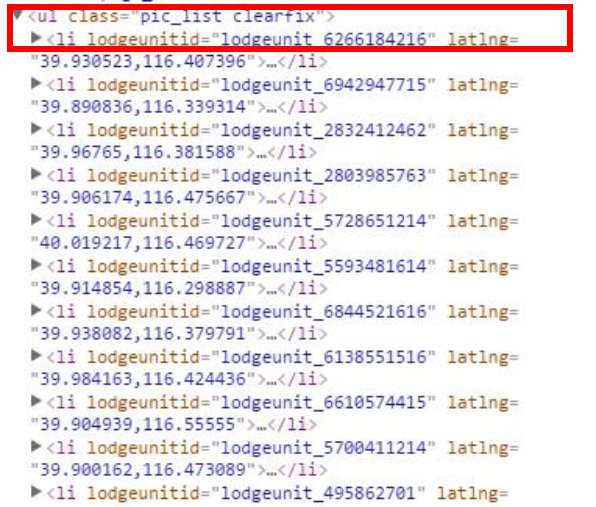
2 xpath是先抓大在抓小,找循环点。
二、代码
import requests
from lxml import etree
import pymongo
client = pymongo.MongoClient('localhost', 27017)
test = client['test']
xiaozhu = test['xiaozhu']
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(str(i)) for i in range(1,14)]
def get_info(url):
html = requests.get(url,headers=headers)
selector = etree.HTML(html.text)
commoditys = selector.xpath('//ul[@class="pic_list clearfix"]/li')
for commodity in commoditys:
address = commodity.xpath('div/div/a/span[@class="result_title hiddenTxt"]/text()')[0]
price = commodity.xpath('div/span[@class="result_price"]/i/text()')[0]
lease_type = commodity.xpath('div/div/em/text()')[0].split('/')[0].strip()
bed_amount = commodity.xpath('div/div/em/text()')[0].split('/')[1].strip()
suggestion = commodity.xpath('div/div/em/text()')[0].split('/')[2].strip()
infos = commodity.xpath('div/div/em/span/text()')[0].strip()
comment_star = infos.split('/')[0] if '/' in infos else '无'
comment_amount = infos.split('/')[1] if '/' in infos else infos
content = {
'address':address,
'price':price,
'lease_type':lease_type,
'bed_amount':bed_amount,
'suggestion':suggestion,
'comment_star':comment_star,
'comment_amount':comment_amount
}
xiaozhu.insert_one(content)
for url in urls:
get_info(url)
三、简单分析
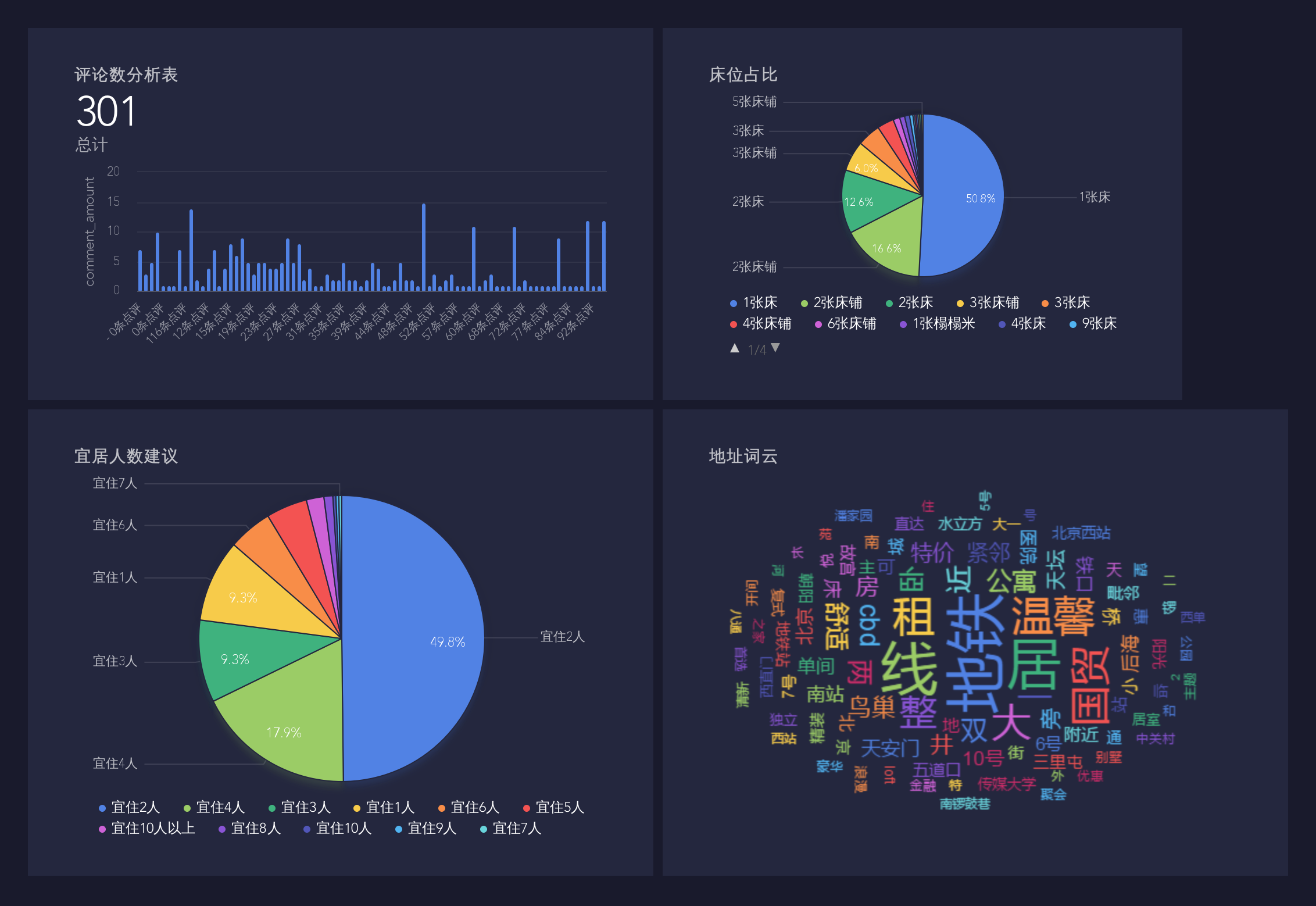
上次许多人问我,数据图是用什么做的,在这里给大家说一下:是用个人BDP做的,很简单,但个人版连接数据只支持csv和excel格式的数据,所以我的做法是:先导入mongodb,然后通过mongodb的导出功能导出为CSV的数据进行分析,导出csv格式的代码:
mongoexport -d test -c xiaozhu --csv -f address,price,lease_type,bed_amount,suggestion,comment_star,comment_amount -o xiaozhu.csv
1 -d数据库
2 -c表数据
3 -f表示要导出的字段
四、问题
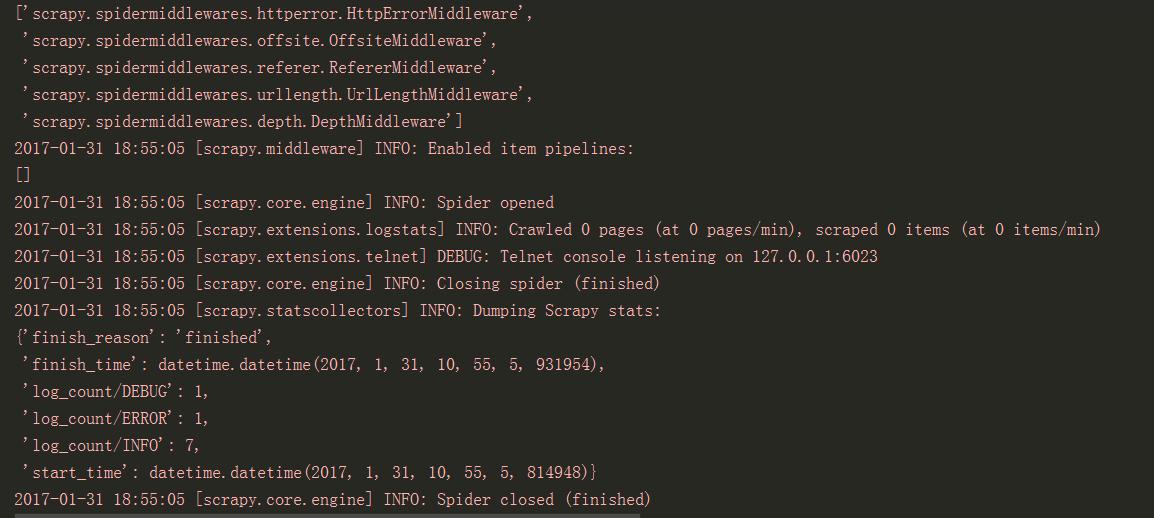
学习xpath是为scrapy框架做准备,自己捣鼓了二天,写的代码爬不出数据(也是小猪短租的爬取),本人win7系统加python3.5
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



