
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
利用scrapy爬取直播吧NBA首页所有图片
发布时间:2018-07-04
爬这个这个网站主要是因为喜欢看NBA啊,那么多图片,一下拿掉多爽,刚学了scrapy里面的rule用法,顺便练练手
,这次爬虫比较简单,主要是学学rule用法
先看item文件里面的代码,只需提取两个数据
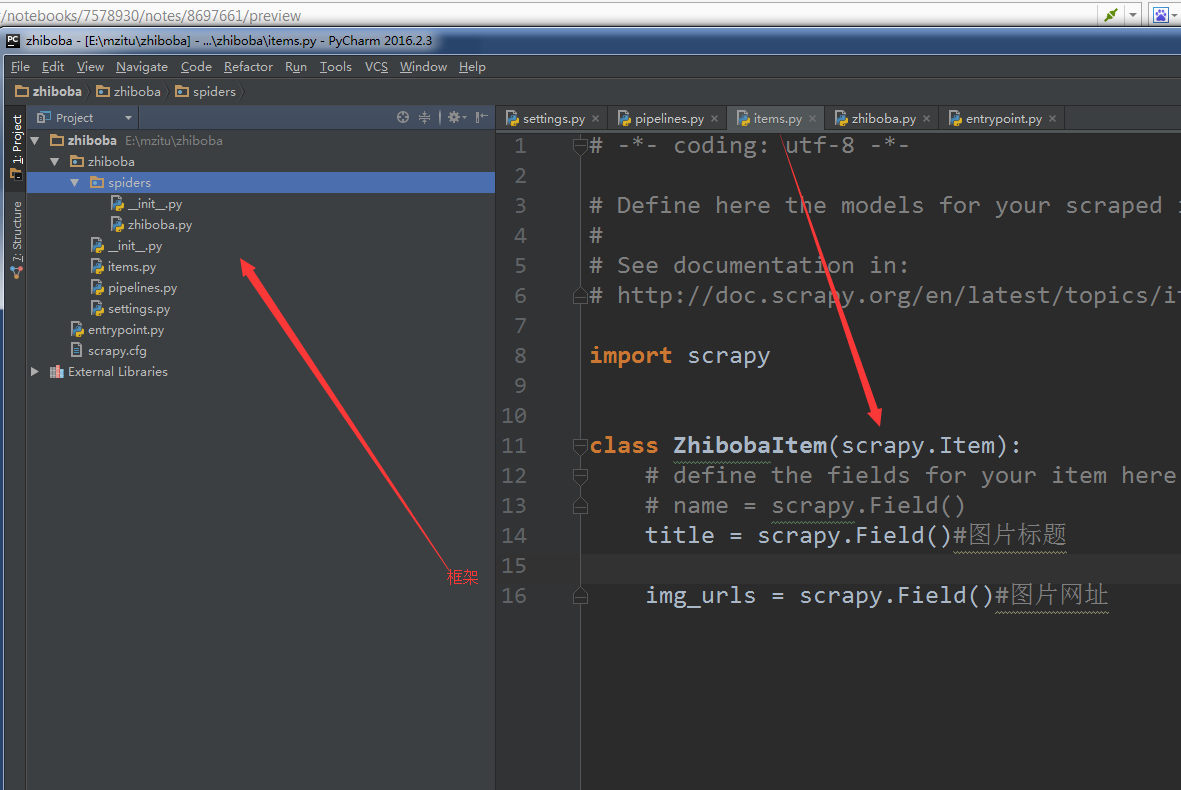
Paste_Image.png
下面是pipelines代码,用来处理item的数据
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from zhiboba import settings
import os
import requests
class ZhibobaPipeline(object):
def process_item(self, item, spider):
path = str(item['title']).strip().replace("?",'').replace('!','').replace('"','')
isExists = os.path.exists(os.path.join("E:\zhiboba", path))#判断这个文件在不在
if not isExists:
print(u'创建一个名字叫做',path,'的文件夹')
os.makedirs(os.path.join("E:\zhiboba", path))
#os.chdir("E:\zhiboba"+path)
for img_url in item['img_urls']:
img_name = img_url.split('/')[-1]
try:
os.chdir("E:\zhiboba\\"+path)#这是切换到这个路径
img = requests.get(img_url)
f= open(img_name,'ab')
f.write(img.content)#写入文件
f.close()
except:
print('图片已经存在')
continue
return item
下面是zhiboba文件,爬虫主程序
from scrapy.spiders import CrawlSpider,Rule,Request
from scrapy.linkextractors import LinkExtractor
from zhiboba.items import ZhibobaItem
import re
import lxml
import requests
from lxml import html
class myspider(CrawlSpider):
name = 'zhiboba'
allowed_domains =['tu.zhibo8.cc']
start_urls = ['http://tu.zhibo8.cc/nba']
rules = (
Rule(LinkExtractor(allow=('/album/')),callback='parse_item',follow=False),
)#匹配图片的url
def parse_item(self,response):
item = ZhibobaItem()
item['title']= response.xpath('//*[@id="main"]/h1/text()').extract()[0]
page = response.xpath('//*[@id="main"]/div[2]/div/text()').extract()
max_page = re.findall(r'\d\d|\d',str(page),re.S)[0]#有些页数双数,有些单页,所以要用|表示或,
匹配每个类别的最大的页数
img_urls=[]
for page in range(1,int(max_page)+1):#这里根据有图片页数构造每出一个图片链接
link=response.url+'/'+str(page)
data= requests.get(link)
data.encoding='utf-8'
selector = lxml.html.document_fromstring(data.content)
url =selector.xpath('//div[@id="image_wrap"]/img/@src')[0]#这里的正则跟scrapy有点不同,前面要加div
img_urls.append(url)
item['img_urls']=img_urls
#print(item)
return item
这里对于rules的,上网找到了一个比较好的解释,来自卧槽哥的,自己改了改
我只说说rules这一块儿
表示所有response都会通过这个规则进行过滤匹配、匹配啥?当然是后缀为/album/的URL了、callback=’parse_item’表示将获取到的response交给parse_item函数处理(这儿要注意了、不要使用parse函数、因为CrawlSpider使用的parse来实现逻辑、如果你使用了parse函数、CrawlSpider会运行失败。)、follow=True表示跟进匹配到的URL,False则相反(顺便说一句allow的参数支持正则表达式、虽然我也用得不熟、不过超级好使)
至于我这儿的allow的参数为啥是’/album/’;大伙儿自己观察一下我们需要获取想要信息的页面的图片URL是不是都包含/album/结束的?明白了吧!
然后rules的大概运作方式是下面这样:
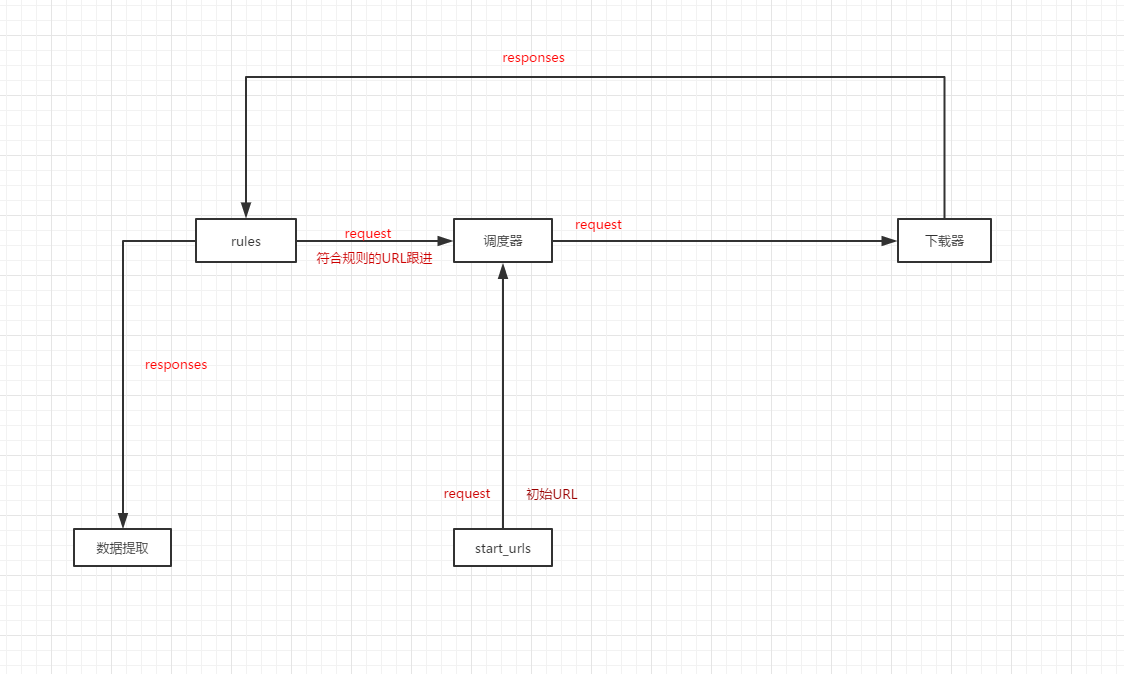
Paste_Image.png
以后自己也可以当笔记来看看
最后提一提,在scrapy使用requests库,深深感觉到自己的low逼,但是没办法啊,谁叫我技术差呢【捂脸】,上张效果图
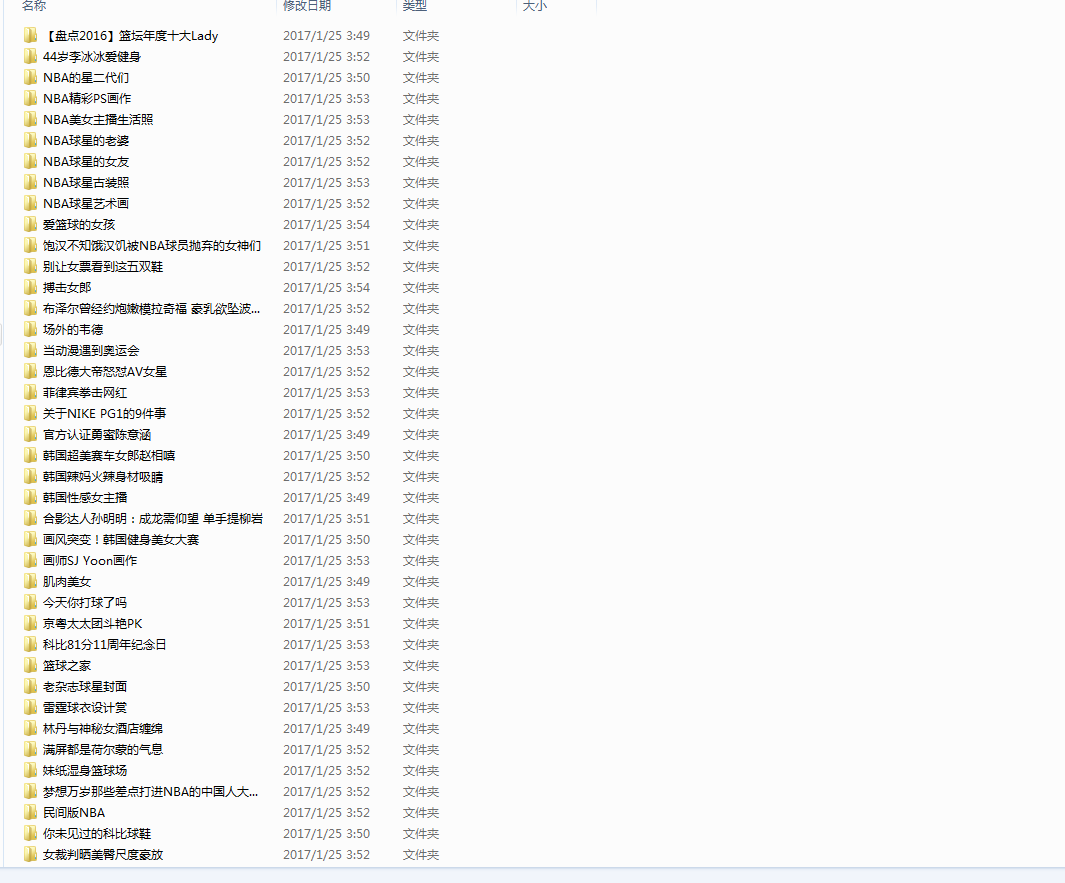
Paste_Image.png
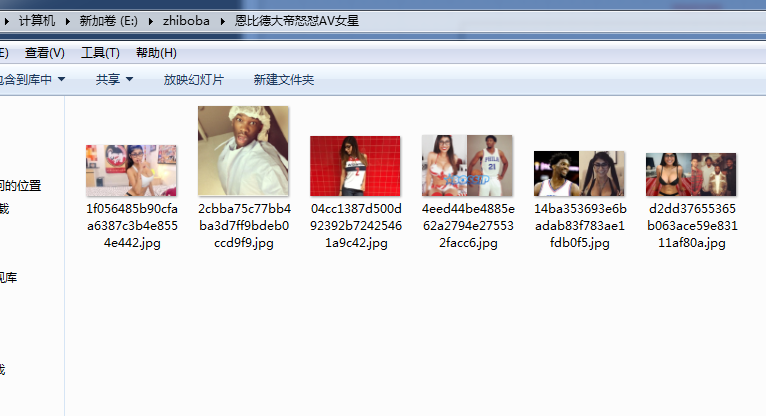
Paste_Image.png
感觉直播吧的图也是越来越没节操了
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



