
 实名认证
实名认证
 未实名
未实名
 已实名
已实名
 订单记录
订单记录 退出登录
退出登录
爬虫url去重——Berkeley DB 性能测试
发布时间:2018-07-04
2017年3月7日更新
berkley db 还是不适合应用在生产环境中。今天我ctrl+c强制关程序,berkley db 一直报错:
(-30973, 'BDB0087 DB_RUNRECOVERY: Fatal error, run database recovery -- BDB0060 PANIC: fatal region error detected; run recovery')
这太不健壮了,而且网上资料太少了。
决定放弃这个。。。
爬虫中需要用到大规模url去重,在网上搜索到Berkeley DB,发现非常适合。优点如下:
1、嵌入式数据库,插入和查询非常快,比redis要快(主要是没有网络开销)
2、python中使用非常简单方便
测试流程:
1、生成1000w数字,插入db
2、随机生成一个数字,进行查询
3、生成1000w数字,然后算出md5
4、随机生成一个数字的md5,进行查询
我的测试代码:
代码地址:
#coding:utf8
import bsddb3
import time
import random
import hashlib
test_num = 10000000
def md5(s):
return hashlib.md5(s).hexdigest()
def insert(db):
t0 = time.time()
for i in xrange(test_num):
db[str(i)] = None
print time.time() - t0
def insert_md5(db):
t0 = time.time()
for i in xrange(test_num):
db[md5(str(i))] = None
print time.time() - t0
def query(db):
i = random.randint(0,test_num)
t0 = time.time()
print db.has_key(str(i))
print time.time() - t0
def query_md5(db):
i = random.randint(0,test_num)
t0 = time.time()
print db.has_key(md5(str(i)))
print time.time() - t0
def main():
db1 = bsddb3.hashopen('test1.db', 'c')
#插入1000w整数
insert(db1)
query(db1)
#插入1000w整数得到的md5
db2 = bsddb3.hashopen('test2.db', 'c')
insert_md5(db2)
query_md5(db2)
if __name__ == '__main__':
main()
测试结果:
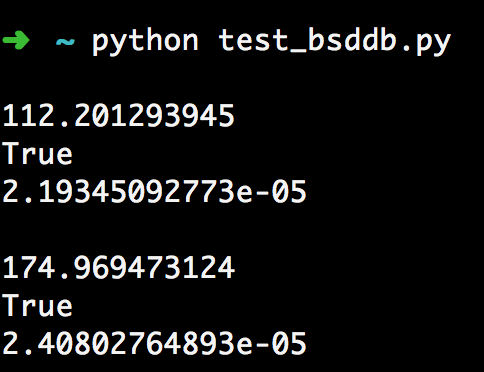
测试结果.png

文件大小.png
结论:
1、插入1000w数字只要112s
2、1000w的md5数据大小为640M
3、一次查询的时间为10us
热门文章
行业早报2019-01-15 nginx+php 开启PHP错误日志
nginx+php 开启PHP错误日志
行业早报2019-01-15
为什么你说了很多遍,对方还是不听? 2018-09-25
行业早报2019-01-15
【Ruby on Rails实战】3.1 宠物之家论坛管理系统介绍
行业早报2019-01-15
从凡人到筑基期的单片机学习之路
行业早报2019-01-15
jmeter单台大数量并发
行业早报2019-01-15
Go在Windows下开发环境搭建
行业早报2019-01-15
ES-科普知识篇
行业早报2019-01-15
Hbase 之 由 Zookeeper Session Expired 引发的 HBASE 思考
行业早报2019-01-15
谷歌大脑专家详解:深度学习可以促成哪些产品突破?
行业早报2019-01-15
EventLoop
相关推荐



